
티스토리 뷰
step 1. nltk 패키지 설치하기
nltk.download()
step2. nltk패키지 불러오고 제대로 설치되었는 지 테스트하기
import nltk
from nltk.corpus import brown
brown.words()step3. 불용어 제거를 위한 불용어 사전 로딩
from nltk.corpus import stopwords
from nltk.tokenize import RegexpTokenizer
미국 도날드 트럼프 연설문 불러와서 형태소 분석하기~! (필요하신 분은 아래 텍스트 파일 다운로드 해주세요~!)
step4. 텍스트 파일 불러오고 형태소 분리하기
data1 = open('파일경로/파일이름.txt').read()
from nltk.tokenize import WordPunctTokenizer
tokenizer = WordPunctTokenizer()
new_data2 = tokenizer.tokenizer(data1)
print(new_data2)But! 축약형(ex. don't)의 경우 축약된 단어를 분리하지 말고 출력하고 싶을 경우 정규식을 사용하면 됨
from nltk.tokenize.regexp import RegexpTokenizer
tokenizer = RegexpTokenizer("[\w']+")
new_data3 = tokenizer.tokenize(data1)
print(new_data3)step5. 불용어 제거하기
data4 = [each_word for each_word in new_data3 if each_word not in stopwords.words()]
data4step6. 단어별로 언급빈도 집계하기
from collections import Counter
data5 = Counter(data4)
data6 = data5.most_common(100)
data7 = dict(data6)step7. 집계된 단어를 그래프로 표시하기
import matplotlib.pyplot as plt
plt.figure(figsize = (10,4))
g_data4 = nltk.Text(data4, name=" 다빈도 단어 그래프 출력하기")
g_data4.plot(20)⇨그래프 출력 결과

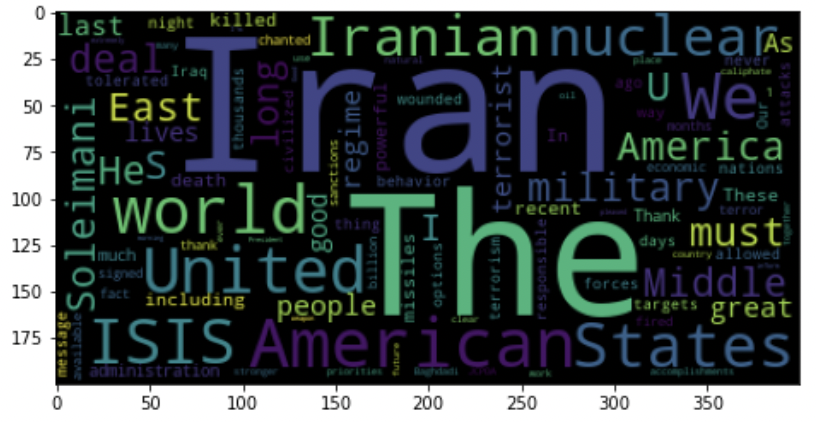
step8. 워드 클라우드 그리기
from wordcloud import WordCloud
import matplotlib.pyplot as plt
wordcloud = WordCloud(relative_scaling = 0.2, background_color = 'black').generate_from_frequencies(data7)
plt.figure(figsize=(10,4))
plt.imshow(wordcloud)
plt.axis('on')
plt.show()⇨워드 클라우드 출력 결과
step9. 추가로 불용어 제거한 후 워드 클라우드 그리기
파일은 아래 첨부!
stop_words = open('파일경로/파일이름.txt').read()
new_data4 = [each_word for each_word in data4 if each_word not in stop_words]
new_data4step10. 1 글자 이하이거나 10 글자 이상인 단어 삭제하기
new_data5 = []
for i in range(0,len(new_data4)):
if len(new_data4[i]) >= 2 | len(new_data4[i]) <= 10:
new_data5.append(new_data4[i])
data5 = Counter(new_data5)
data6 = data5.most_common(100)
data7 = dict(data6)
wordcloud = WordCloud(relative_scaling = 0.2, background_color = 'black').generate_from_frequencies(data7)
plt.figure(figsize=(10,4))
plt.imshow(wordcloud)
plt.axis('on')
plt.show()⇨클라우드 출력 결과

step11. 다빈도 단어를 그래프로 출력하기
plt.figure(figsize=(10,4))
g_data5 = nltk.Text(new_data5, name="다빈도 단어 그래프 출력하기")
g_data5.plot(50)
'파이썬' 카테고리의 다른 글
| 결측치 처리 (0) | 2023.03.26 |
|---|---|
| 파이썬 활용하여 자동으로 이메일 보내기 (0) | 2021.06.13 |
| 여러가지 통계분석 (0) | 2021.06.13 |
| (MAC OS)matplotlib을 이용한 다양한 그래프 그리기 / bokeh 그래프 그리기 (0) | 2021.06.13 |
| (MAC OS) matplotlib를 이용한 그래프 그리기 (0) | 2021.06.13 |